

So people, do you have slow running flows?!?! If so, WHY?! I’m guessing you haven’t read my 5 tips for improving performance in Power Automate flows… oh wait… I’m only just giving them to you! Well, here goes it… here’s 5 tips for improving performance in your Power Automate flows! 🤩
Pick the correct data source 🔢
So the first tip is more of a technical architecture point, and it is to pick the correct data source. Generally speaking, if you’re working with an extra large t-shirt sized type solution with high volumes of data being moved between places using Power Automate, you won’t want to be working with a data source like SharePoint for example.
Each connector will have different limits when it comes to throttling and API calls, so using the correct data source and corresponding connector plays a big role here!
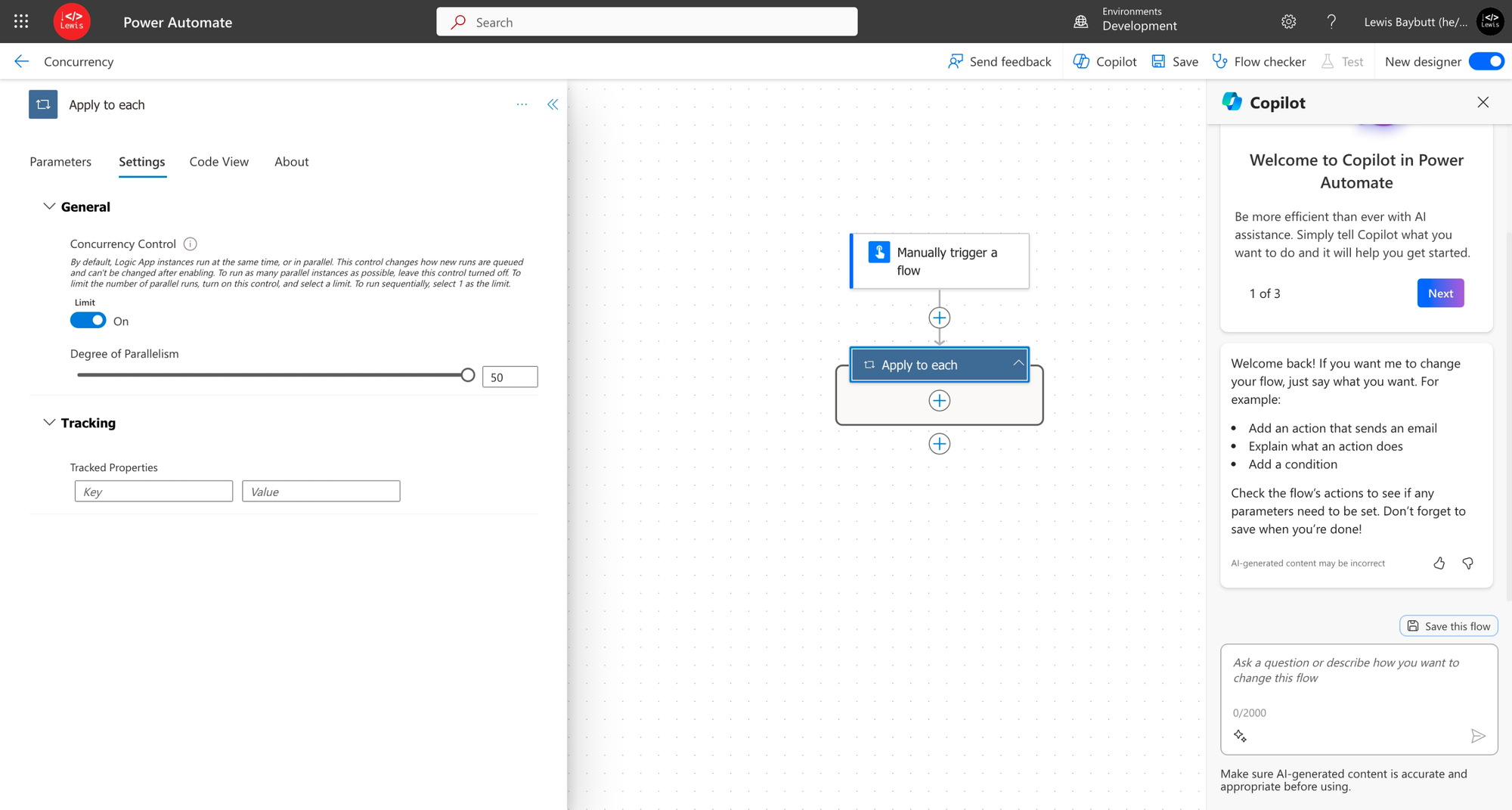
Use concurrency in apply to each
If you have flows with apply to each loops where you’re running an action on multiple records within an array that you’re pointing the actions at, an important performance factor is to not run the actions on each record sequentially i.e. one after the other. By using concurrency in apply to each loops you’ll be able to have the actions run across all many of the records in the array in parallel!
To enable this in your flow, select the Settings pane on your apply to each action and enable the concurrency control. Then increase the degree of parallelism as high as the number of concurrent runs you want to run at once.
OData Filter Query
Are you using huge API calls in your Power Automate flows by returning huge amounts of records like an entire view that isn’t that filtered down in Dataverse or a whole list from SharePoint and then filtering out the things you don’t need with further logic in your flow?
This could be slowing your flows down massively and you don’t need to collect all of that data in the first place? Start moving your filters to the server side using a filter query when using a get rows type action or an API GET call to retrieve data!
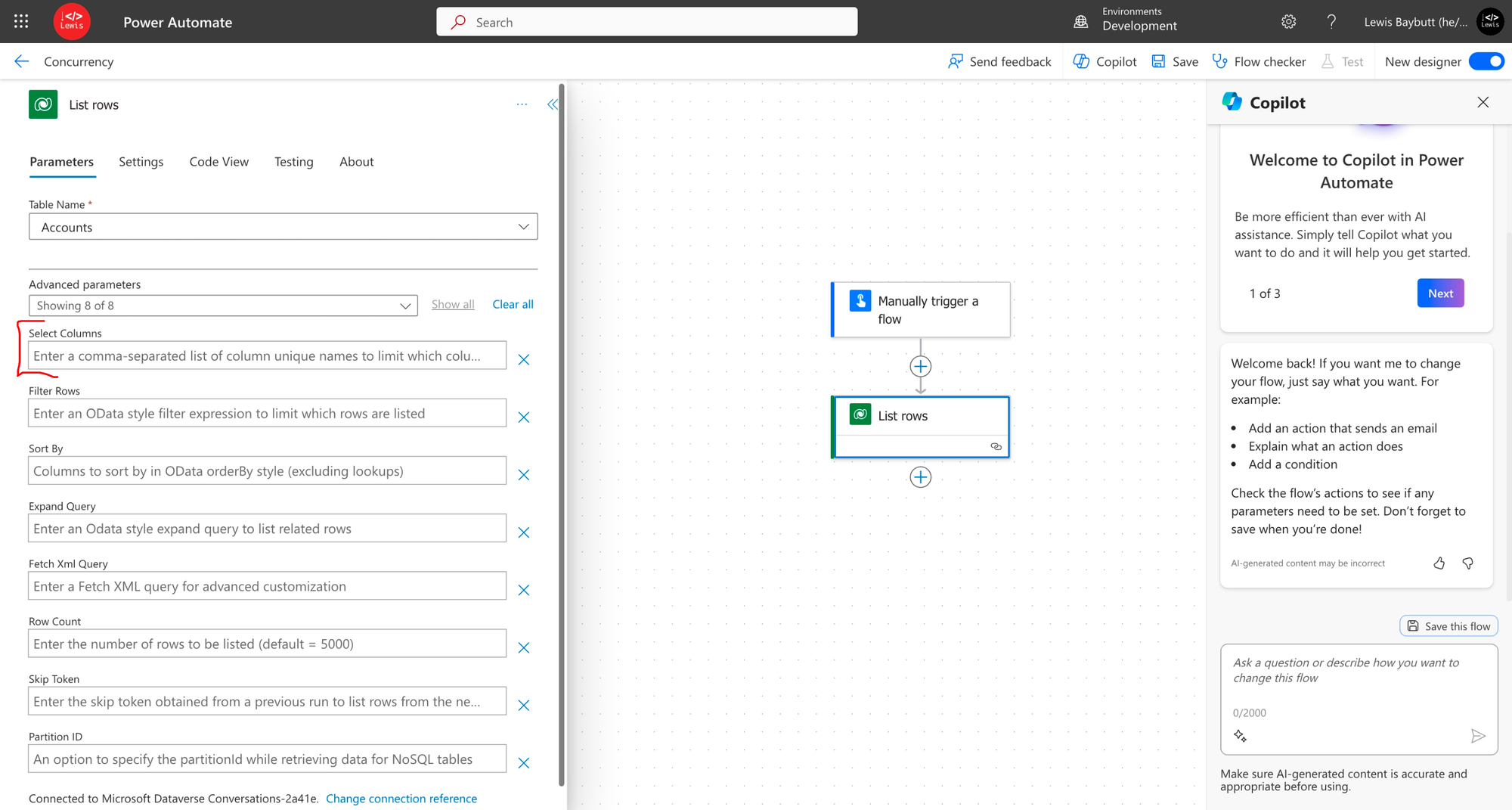
Limit table columns
The next thing we can do to improve API calls to data sources is to limit the columns we return. It might be that we need to return a certain set of records from the data source which we’ve already controlled with a filter, but we’re not actually going to use all of the values in all of the columns that are available for those records / that table. So yet again, we’re returning unnecessary data which will slow down our automation in these areas!
In these cases we can limit the table columns we return on various steps and when using API calls to the data source. Check out the Dataverse example below…
Avoid on-premise data sources and actions
As a general rule of thumb I try to avoid using on-premise data sources and actions as an early architecture decision when building solutions. These can slow down performance due to increased latency and they can also introduce increased levels of complexity to the automation flow.
I tend to recommend to try to stick to cloud based solutions for data where possible and to steer a little clear of on-premise related actions where it is possible!